프랑스에 기반을 두고 있는 인공지능 스타트업 미스트랄 AI (Mistral AI)에서 7월 20일 음성 인식 모델 Voxtral 모델을 전격 공개했다. 이번 출시로 음성 AI 시장의 판도를 바꿀 이정표로 평가를 받고 있으며 오픈소스로 공개하여 개발자들에게 자유롭게 다운로드하고 로컬환경에서 호스팅할 수 있도록 했다.
그동안 음성 인식(ASR)기술이 가진 한계를 뛰어넘는 비전을 제시했다. 단순히 음성을 텍스트로 변환하는 것을 넘어 음성 데이터에서 직접 질문에 답하고, 내용을 요약하며 특정 함수를 호출하여 워크플로우를 실행하는 음성 이해 기능을 핵심으로 한다. 이는 기존 음성 AI가 제공하는 기능의 범위를 확장하는 것이다.

Voxtral은 크게 두가지 버전으로 나눌 수 있다.
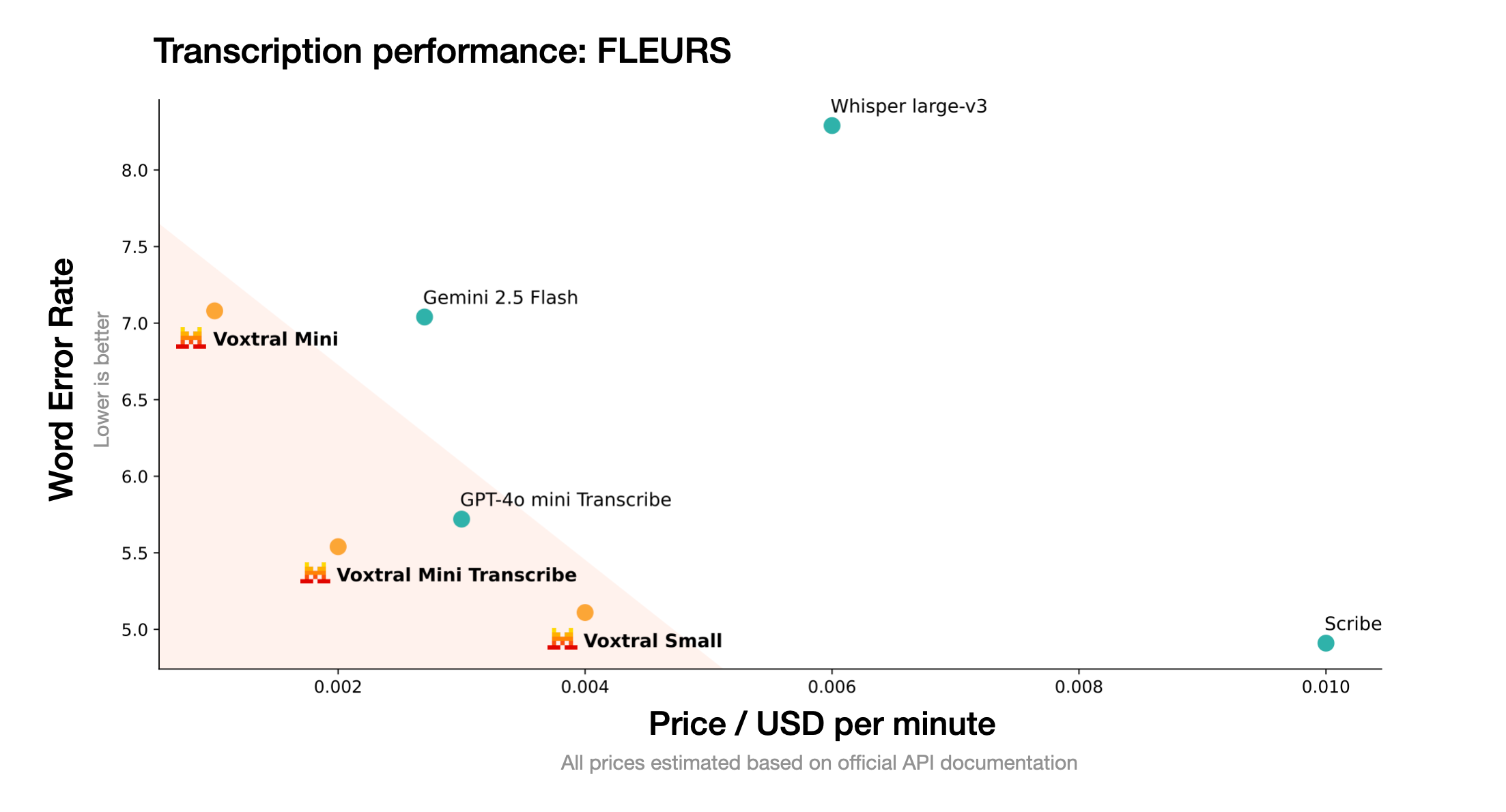
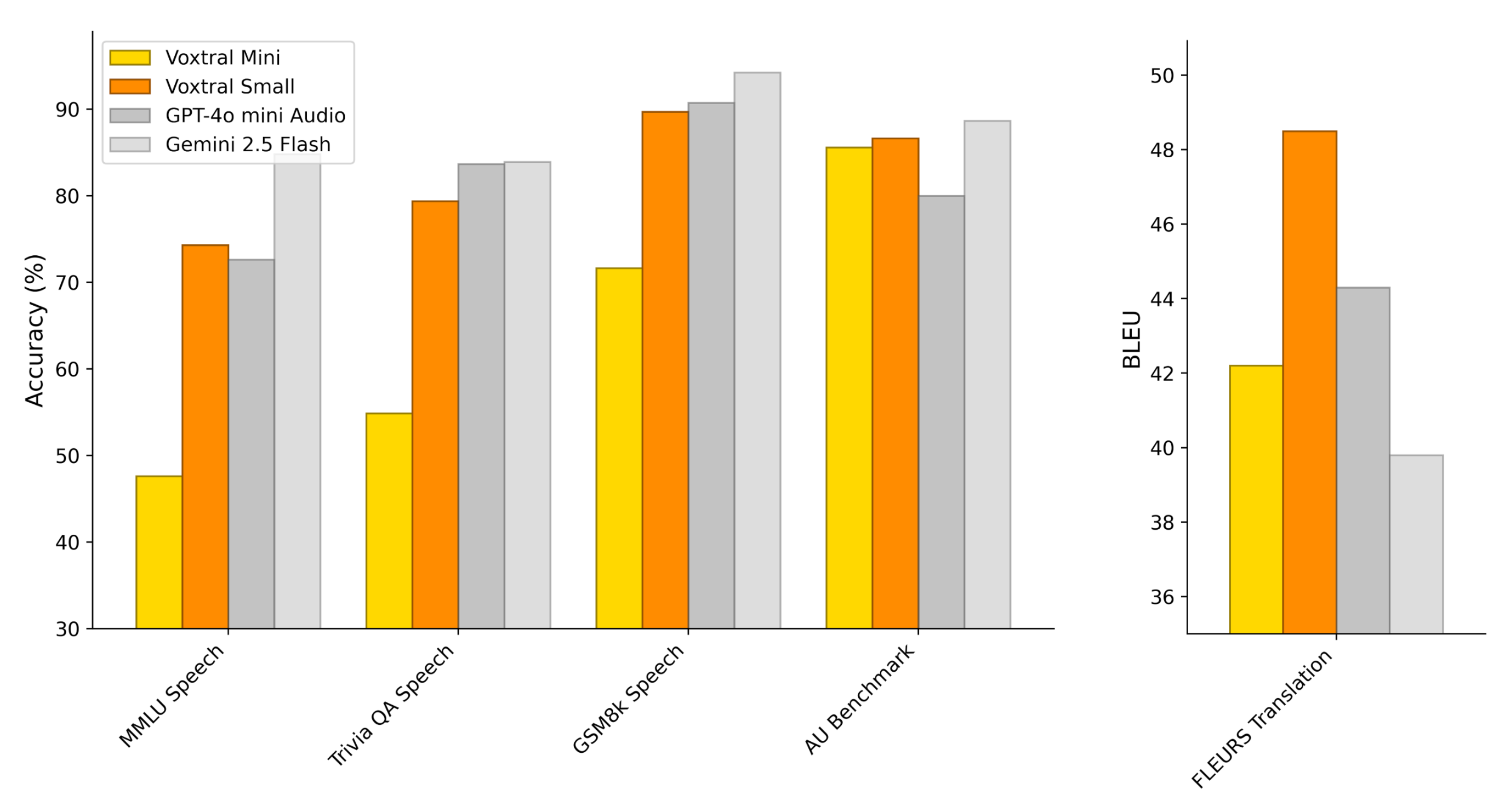
Voxtral Small(24B파라미터)는 대규포 배포 및 클라우드 환경에 적합한 고성능 모델이며 최고 수준의 정확도를 제공하며 워드 에러율 감소에 중점을 둔다. 최상위 모델들과 비교 했을때 비슷한 성능을 보여 준다.
Voxtral Mini (3B 파라미터)는 단일 GPU 또는 엣지 디바이스와 같은 제한된 환경에서 실시간 실행이 가능한 경량 모델이다. 데이터가 로컬환경에 머물러야 하는 경우에 효과적으로 사용할 수 있다.
32k 토큰에 달하는 긴 컨텍스트 창을 지원하여 최대 30분 분량의 음성 또는 40분 분량의 오디오를 인식 가능하다. 이는 긴 회의록 작성이나 강의 내용 분석 등 장시간 오디오 처리에서 탁월한 강점을 제공한다. 이번 Voxtral 모델 출시로 음성 기반 애플리케이션 개발에 새로운 활력을 붙어넣을 것으로 기대된다.
https://huggingface.co/mistralai/Voxtral-Small-24B-2507
https://mistral.ai/news/voxtral
https://docs.mistral.ai/capabilities/audio
'IT이야기' 카테고리의 다른 글
| 프론티어 모델을 알려주세요! (0) | 2025.07.22 |
|---|---|
| 허깅페이스, 작지만 강한 모델 SmolLM3 등장 (0) | 2025.07.21 |
| xAI, 인공지능 모델 그록 4 공개 (0) | 2025.07.16 |
| 문샷 AI, 가장 큰 규모의 Kimi k2 모델 오픈소스로 공개 (0) | 2025.07.13 |
| 즈푸AI, 추론형 AI 모델 GLM-4.1V-Thinking 공개 (2) | 2025.07.10 |



